
GPT can use a web browser to answer questions.
When embedded in a REPL environment and prompted to strategize and monologue, agent-like behavior emerges. The agent can solve multi-step problems that involve going to pages, following links, reading the next page, etc.
Thread ↓
The real HN pages showing those answers:
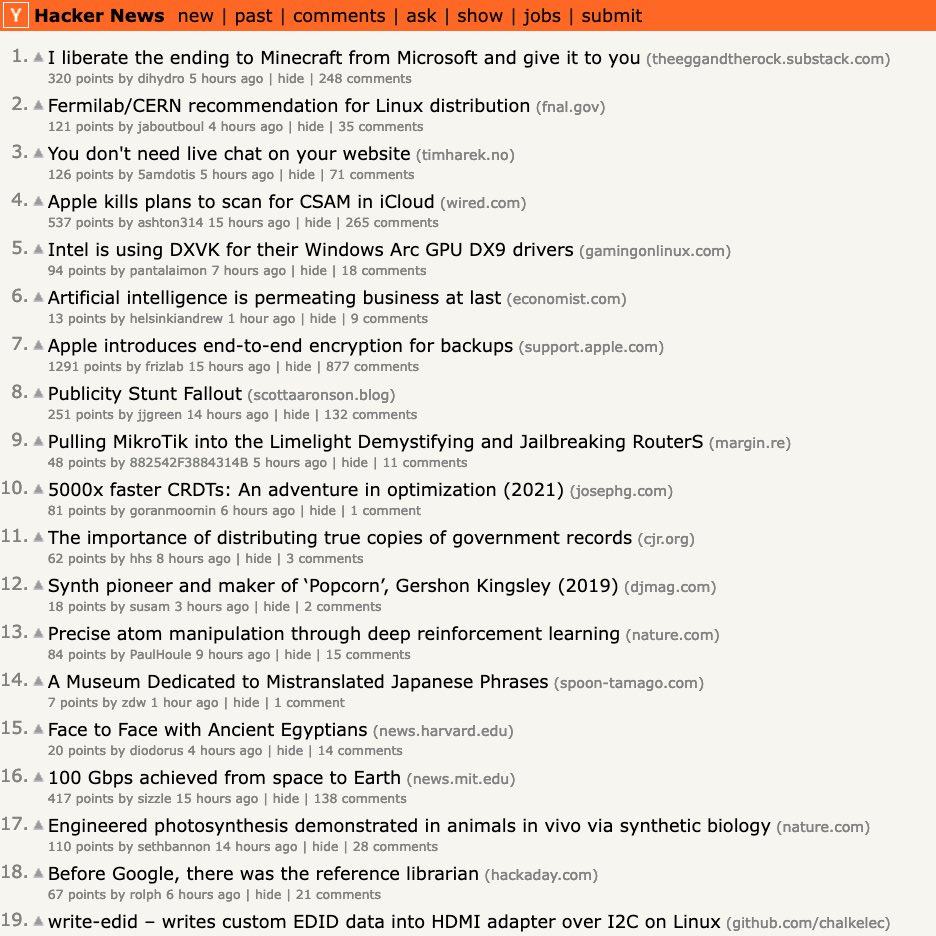
Explanation of the system described in the diagram:
The process here involves several different prompts pipelined together in a recursive fashion to result in agent-like behavior. 1/
The first step is to send the user command into a simple classifier prompt that determines if it needs the internet. If it does, it rewrites the user's query into a search command for the next prompt. 2/
The next prompt involves embedding GPT3 in a mock REPL that is given the overall goal of fulfilling the command from the previous step. It does this by having the ability to use the REPL to fetch HTML from a URL, and apply an english query to it. 3/
This english query is applied to chunks of the HTML. You have to use chunks because most pages are larger than GPT3's context window. Extract all the results of this chunked processing and send it to a final aggregation prompt. 4/
Send this aggregated result back to the REPL from the previous step. At this point, the agent in the REPL can either choose to emit the result if the goal has been met, or keep working. Some REPLs need multiple steps, e.g. google -> find page -> look for result on that page 5/
This REPL output is then given back to the prompt that gets the output from the "Assistant". GPT3, choosing the Assistant's next response, will pull data from the now-available REPL output. Voila. 6/
Some notes: Internal monologue is a key ingredient. It gives the agent opportunity to make explicit note of unexpected or interesting new data and adapt its strategy. It also helps with a narrative structure that prompts agent-like behavior. 7/
More notes: Web pages get chunked because they are too big to fit in GPT's context window. It has to "look at" a sliding window through the page. This chunking and aggregation method is rudimentary and can be improved with semantic embeddings. For a future thread! /end
100% of Profits Are Donated To Research-Backed Charities.